
[Critical AI’s Guest Forum welcomes writers on topics of potential interest to our readers inside and outside of the academy. Below is the edited script from the co-facilitator presentation that Sean Silver (English, Rutgers) made during THE ONTOLOGICAL LIMITS OF CODE, the sixth in a series of workshops organized through a Rutgers Global and NEH-supported collaboration between between Critical AI@Rutgers and the Australian National University. For the blog on this series by Mark Aakhus (Communication, Rutgers) click here.]
by Sean Silver (English, Rutgers)

My mandate this evening is to share a few observations about Zachary Lipton’s 2017 essay “The Mythos of Model Interpretability,” which takes up an important issue that emerges any time machine learning meets critique. In one sense, the problem of model interpretability is simply one version of the more general problem of the emergent behavior of complex systems, like weather or social groups or neural networks or whatever. We are used to accepting that the behavior of complex things can’t be known in advance, except probabilistically. We might want to understand weather patterns better, but we don’t expect them to explain themselves. But the case is different with complex systems that we make ourselves, like predictive algorithms. When these predictive models behave in ways we don’t expect—or approve—then we, quite correctly, I think, want explanations. One response to this desire is a call for models which are themselves interpretable, not merely in their behavior, but in their construction. Such a transparent model would presumably be explanatory—certainly in the logic of its construction, but possibly also in its effects. We would like to know why it has behaved as it has when deployed in the sorts of novel situations which computationalists like to call “in the wild”; better, would be to know how it will behave in advance.
Lipton’s intervention in this conversation is to suggest that we have been unclear about what we mean by “interpretability”: “interpretability,” he suggests, “is not a monolithic concept, but in fact reflects several distinct ideas.” His essay takes a step towards correcting this aporia by compiling a non-exclusive review of approaches current in the computational literature: different things that have been meant by “interpretability.” Lipton has, in other words, undertaken a modeling operation of his own, indeed a modeling operation on a corpus of natural language documents; my job is to begin the task of interpretation.
I am, however, not going to do it in Lipton’s footprints. I’m not going to offer interpretive remarks on remarks on interpretability. I’m rather going to heed Lipton’s own injunctive conclusion, that “any assertion regarding interpretability should fix a specific definition,” which I will do along the way, suggesting that interpretation is a theoretical act built into certain kinds of modeling enterprises, but not others. Rather, my intention is to untie the interpretive knot in Lipton’s essay by thinking about what we mean when we say “model,” and I’m going to do it with reference to a collaborative project that has been dedicated to finding productive sympathies between the eighteenth-century sentimental novel and the computational field known as sentiment analysis, what I and Andy Franta are calling a literary approach to computational analysis.
Lipton’s essay is what conceptual historian Reinhart Koselleck would call a synchronic review of the model concept; that is, Lipton has summarized aspects of model interpretability at a moment in history, which happens to be a moment so recent that it is fair to call it current. In response, I’m offering a diachronic history, sacrificing a great deal of specificity about the current discourse to construct a longer narrative or story about how our discourse arrived here.

If I read Lipton’s essay correctly, there are at least two major senses of the word model operating in the interpretability discourse; these appear frequently to be mistaken for one another, in such a way that the properties and expectations for the first become foisted upon the second. The first sort of model is the kind of model which R.I.G. Hughes, in an important essay in philosophy of science, calls “theoretical.” A theoretical model holds some sort of referential similarity with the object or idea that is being modeled, and is constructed in such a way that we can better understand the thing to which it refers. Sometimes we use these in development, when we want to mock up something in order to understand design challenges. Sometimes, we build them after the fact, when something has occurred and we want to understand the structure of the event or how it happened. Figure 1 is an early instance of a model built to understand an everyday phenomenon: Galileo’s model of an object in freefall. It is a modeling operation, since it is built, according to some theory, better to understand the effects of gravity.
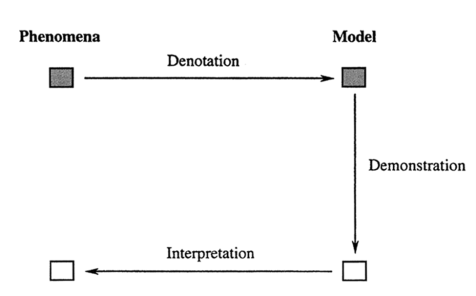
Models like these are implied in the sorts of cognitive activities we now call “extended” or “embodied”: these are thinking operations akin to what the seventeenth-century theorist, Robert Hooke, called “excogitation“—a process that begins in the head, but proceeds to the hand, then back to the head, and so on, or vice versa: from hand to head and back again. It is akin to what the novelist Michael Ondaatje has called “thinkering,” or the theorist Andrew Pickering, “meddling” or “the mangle of practice.” Hughes’s “theoretical” schema (Figure 2) is a description of this sort of excogitative process; it is a model (one of many) of this way of thinking about models, especially of the theoretical sort. A phenomenon is represented in a model via a process Hughes calls “denotation”; the model is manipulated to elicit one or more of its features; and the lesson learned there is returned to the phenomenon by way of interpretation. Subsequently, a new model might be employed, and so on, and so forth. Now, this isn’t the only way to think about thinkering. But it is useful for our purposes because it reminds us that a theoretical model is constructed with interpretation in mind. Inasmuch as it is theorized, it gives rise, step by step, to a moment of illumination. We would therefore expect a model to be interpretable to the extent that it was theorized from the start.

The semantic differential atlas, the mid-century project associated with Charles Osgood, is a theoretical model. Osgood’s hunch was that an entire language could be rendered as a distribution of points in a high-dimensional concept space. Let’s imagine, to the extent that we can, a Euclidean space of fifty dimensions, where every axis in that space is defined by a pair of adjectives: heavy/light, living/dead, crooked/straight, and so on. Figure 3 is a three-dimensional simplification; you’ll have to add the other 47 dimensions in your head. Armed with a rigorous questionnaire and some captive subjects, you might, as Osgood did, now empirically establish the position of as many concept words as you please: so, for instance, “elbow” is neutral with regard to weight, moderately associated with the living pole of the y axis, and strongly associated with crookedness. And so on—for 47 more adjective pairs, then again, for 999 more words. What results is a theoretical model. It is theoretical because it begins with the theory that language is a distribution of concepts in a space defined by experiences—the heaviness of a thing, or its crookedness, and so on; it develops a system of denotation to capture that relationship as a (high-dimensional) space of associations.
When operations are performed on such a model, they teach us something about the model; to the extent that the model denotes the language it represents, those lessons can be returned as a greater understanding of the phenomenon they capture. Osgood was a gifted statistician, and noticed, entirely through statistical manipulation, that the fifty values for each word in his hypothetical concept space tended to reduce to three factors, which he called potency (like living/dead, or strong/weak), concreteness (like abstract/concrete, heavy/light), and evaluation (which includes crooked/straight, worthless/valuable, and so on). What is more, by far the most important of these factors appeared to him to be evaluation. Any word could be usefully defined, he supposed, simply by its dictionary definition plus its evaluation score, where the evaluation score captures the often unspoken evaluations we make about something. That is, without asking someone if a given concept is good or bad—but only to rank that concept along the scales of crooked/straight, clean/dirty, honest/dishonest—Osgood was able to place the concept on a generalized evaluation scale, between good (at one pole) and bad (at another).
There are clearly problems with Osgood’s model of natural language in terms of concept space, some of which he intuited. But that model has the advantage of being derived relative to a theory about concepts as collections of adjective-like experiences. When operations are performed on that model, the lessons learned from those manipulations lead us to potential new understandings of the relationship between natural language and sentimental charge. What is more, we can trace insights back to the model, since the model is interpretable, through-and-through. The advantage of this approach becomes apparent when Osgood, writing on the eve of the Civil Rights movement, explores nuances of his model’s structuration of race—and can trace the general evaluations of a historicized concept (like Blackness) not only back to its more nuanced articulations in adjective pairs, but also to different articulations among different subjects, reflected in the survey instruments.
The theoretical sort of model came first. That sense of “model” arrived in English in the sixteenth century, though it would not be called “theoretical” until the twentieth. But yet another sense, new enough as not to be registered in my 1971 print edition of the Oxford English Dictionary, would become primary in the literature associated with predictive machine learning. This late twentieth century sense of model signifies a procedure or process that can be put to work for some pragmatic end; and it is in the social sciences (especially with the modernization of statistics in fields like economics and political science), that the concept appears to have developed. This sort of model, which we might call predictive or procedural, starts out with the intention to capture some set of features which are presumed to bear upon a thing in the world (perhaps a vision of how price increases will affect economic growth). We might liken such models to what Roland Kaschek calls a “prescriptive mode,” wherein models are used to offer predictions. But the data-driven, computational sort, like those Lipton discusses, are put to work without any definite preconception of the structure of the problem they tackle, or how they might solve it. That is, they are put to work without interpretation in mind. Lipton is interested in “black boxes,” the sort of “blind” processes which have been heightened in the years since “neural networks” and “deep learning” became dominant machine learning technologies. And he is fairly explicit that these are models of the predictive, rather than theoretical, sort; “the most common evaluation metrics for supervised learning,” he writes, “require only predictions, together with ground truth, to produce a score.” (“Ground truth” refers to an empirical data set, which is known or assumed to be true: one type of such a ground truth is discussed below.)
One instance of this sort of predictive modeling is in the emerging field of sentiment analysis. The whole field is geared towards the identification of sentiment—usually consumer sentiment—in instances of natural language use, especially in “opinionated data” like consumer reviews. Its basic method of prediction is to compile a list of words which are thought to be affective in some way (so-called “sentiment words”); assign each one a single value (akin to Osgood’s evaluation score); and then tally up the values of the words appearing in some corpus of texts. Historically speaking, sentiment dictionaries were compiled through survey or questionnaire; more sophisticated methods begin with such a lexicon, then refine it through an algorithmic process such as a word-embedding model. In machine learning, one basic method is to train a predictive model on a corpus such as ratemyprofessor.com reviews, where user comments are attached to a five-point score. That is what is meant by the system’s “ground truth”: though humanist readers may be surprised by this prosaic usage, “ground truth” in this context is just the pairing of natural language texts with subjective scores. The system of neural weights that emerges is judged successful if the model correctly predicts scores from comments in a fresh batch of data.
Now—none of those predictive models are interpretable in the same sense as theoretical ones. Their purpose is not to be interpreted. They can only be evaluated in terms of the accuracy with which they predict scores from natural language comments. If we want to understand how a simulated neural network produces its prediction, we have to perform an additional modeling operation. Since such a system retains a record of the training process in its neural weights, it is possible to extract a theoretical model, which would be superficially similar to the high-dimensional concept-space of Osgood’s semantic differential. This is what Figure 4 is; it is a mocked-up model of a model: a visualization of 3-dimensional vector space, populated with the same concept words as in Osgood’s concept-space. Like Osgood’s semantic differential, the word-embedding model presents words in high-dimensional space—200 or more axes. And it can contain the same words. Here, however, is where the similarities end. If we want to know the evaluation of a word in Osgood’s semantic differential, not only can we know it instantly, but we can also trace it back to a set of fine-grained adjective pairs. If we want to know the evaluation of a word in a word-embedding model, we have to infer it somehow through additional mathematical operations—like finding its nearest neighbors by Euclidean distance or cosine similarity: so, we would figure out that elbow is associated with crookedness and life by finding those words—or, really, collocations of words as concepts—somewhere nearby.

Of course, we can continue to build models of models in an effort to better understand a neural network: and, if we filter these insights back through the assumptions first brought to the enterprise of finding data, and designing the predictive process to match comments to scores, presumably we can learn something about the corpora from which they were derived. But because this model was not built with a theory of its object in mind– because it is not theoretical– it is also not interpretable in the same way. Interpretation instead involves further, theorized interventions, or, more model-building.
I have made a distinction between two kinds of models: theoretical models that set out to offer an interpretable reference and machine learning models that use data-mining to offer predictions without presupposing any theory of the phenomena upon which they are trained. Though these distinctions are not absolute, they’re worth retaining since they highlight two varieties of knowledge: what Gilbert Ryle calls the difference between knowing how, and knowing that (i.e. Concept of Mind, 25-61). If we say that someone knows how to do something, we are, as Ryle defines it, on the terrain of skill, affordance, or disposition and can judge the result. So, someone can build a model, and that model can perform poorly or well; the model can be simple or cunning, fine-tuned or coarse. But if we say that someone knows that about something, we’re on different territory: we’re talking about the extent to which they understand their object of study and can talk about it intelligently. We are on the ground of theory—a wonderful word, which means vision, especially perfect vision (like the sort of transparency that Lipton suggests we sometimes desire in models).
Ryle’s ultimate point is that this sort of understanding—knowing that—is actually another kind of knowing how. We know how to philosophize, or, Lipton might point out, someone knows how to make a model. It’s worth remembering that theorizing is, in this sense, also a skill, for when we do something intelligently we don’t mean that we do two things (build a model, plus theorize about it). We mean that we do one thing, wherein the theory is built into the performance, with the model’s work referencing this theory in some fundamental way. It is just that knowing that is the kind of knowledge which can be declared, as when we philosophize or theorize, so that a model, built intelligently, is one that we can talk about in terms of an understanding of the phenomenon to which it refers. In Hughes’s terms, a model built intelligently is always already interpretable, because the interpretative element is built in along the denotative axis.
That said, it is not clear to me how this kind of theoretical modeling can enter machine learning, not, at least, as it is currently practiced. For Ryle’s distinction has a further lesson to lend; it is that the total, process-oriented “knowing how” accomplishments of predictive models, which are judged merely by the accuracy of their performance, do not lend themselves to the sorts of declarative knowledge which interpretation demands. Declarative knowledge is a different sort of thing, Lipton points this out, in a surprising way. He says that transparency—which is a sort of limit-case of theoretical interpretability, or the summary view implied by theory—”transparency… may be at odds with the broader objectives of AI”; objectives and interpretability, Lipton suggests, are features of different kinds of things, not necessarily the poles of an adjective pair, but in tension, maybe negatively correlated. The fitness of machine learning models is judged based on performance. Interpretation is something additional, some additional modeling operation, but this time, of a theoretical sort. And this seems about right—just about exactly what Ryle’s insight demands.
To be clear, the modeling enterprises Lipton describes here are all done with reference to the (often quite theoretical) tools of computational and statistical analysis; and they are often immensely intelligent in this way. The sort of declarative statements that can be made about them are often of this variety: of the theory (in my example) of simulated neural networks and the operations of linear algebra. But they are undertheorized in the specific Hughes-inspired sense I have been developing here, inasmuch as they are judged based on some performance metric. To interpret a theorized model: that’s still a difficult task, but, since the model is built to be interpretable, the route is clear. But to interpret a model built to find useful patterns in a massive database: that is immensely difficult, since the denotative process is underspecified, or, put differently, the theory behind the construction has to be built up post hoc, painstakingly, in every case. And this, of course, is one dimension of critical AI studies—to take up that burden of interpretation for which a general programme of undertheorization in predictive modeling leaves room.